Apple Silicon の Unified Memory と NVIDIA VRAM、ローカルLLM では何が違うのか 2026年版
Mac Studio M3 Ultra の最大256GB Unified Memory と RTX 5090 の32GB VRAM、ローカルLLMで動く規模はどう違うのか。帯域・PCIeコピー・推論 vs 学習の向き不向きを構造から比較し、Mac/NVIDIA どちらを選ぶべきかを用途別に判断軸付きで解説します。MacBook Pro と RTX ノートPC、Mac Studio と RTX デスクトップ、どちらを選ぶかも用途別に判断軸を提示します。
- #Unified Memory
- #VRAM
- #Apple Silicon
- #M3 Ultra
- #Mac Studio
- #RTX 5090
- #ローカルLLM
- #Llama 3.3
本記事は Amazon.co.jp および各販売店のアフィリエイトリンクを含む場合があります。推奨は性能・コスパ・実機ベンチマーク基準で編集判断しており、提供記事は受け付けていません。詳細は プライバシーポリシー をご覧ください。
結論:モデルサイズ最優先で1台に積みたいなら Mac Studio M3 Ultra(現行最大 256GB の Unified Memory)。推論速度や学習スループットを取るなら RTX 5090 / RTX PRO 6000 Blackwell。 Apple Silicon と NVIDIA は「どちらが上」ではなく、メモリの構造が違う別の道具です。70B 級を「動かしたい」だけなら Mac、「速く動かしたい・学習にも使いたい」なら NVIDIA、というのが2026年5月時点の素直な切り分けになります。
この記事では、Unified Memory と VRAM の何がどう違うのかを構造から整理し、Llama 3.3 70B の実測値・帯域・PCIe コピーの有無・電力までを横並びで比較します。Mac で LLM を動かすか、Windows + GPU を組むかで迷っている方を想定読者にしています。
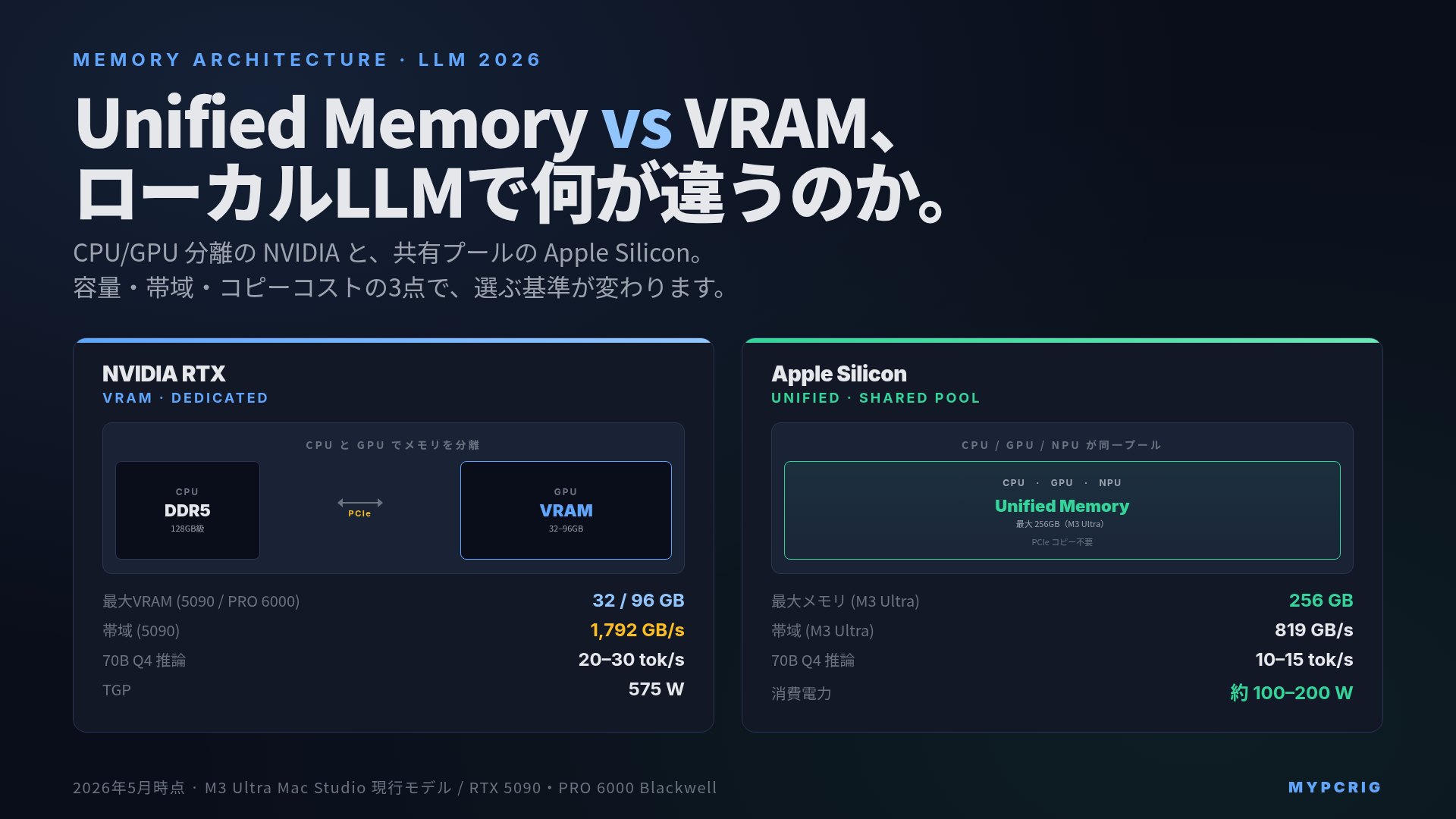
VRAM と Unified Memory:机の置き方が違う
VRAM(Video RAM)は GPU 基板に直接ハンダ付けされた専用メモリです。CPU からは触れず、GPU 演算ユニットの真横にあるため帯域が極端に広い代わりに、容量はチップのパッケージで物理的に上限が決まります。RTX 5090 で 32GB、RTX PRO 6000 Blackwell で 96GB がその物理上限です。
一方、Apple Silicon の Unified Memory は SoC(System on Chip)のパッケージ内に LPDDR5X を貼り付けた構造で、CPU・GPU・Neural Engine が同じメモリプールを共有します。Mac Studio M3 Ultra では現行最大 256GB をまるごとどのコンポーネントからも参照できます。VRAM が「GPU 専用の机」だとすれば、Unified Memory は「CPU と GPU が並んで作業する大きな共有机」です。
この構造の違いが、ローカル LLM の挙動を大きく左右します。
PCIe コピー問題:NVIDIA 側だけに発生する税金
NVIDIA + x86 PC の構成では、モデル重みは最初システム RAM 上に読み込まれ、そこから PCIe 経由で VRAM へコピーされます。Llama 3.3 70B を Q4 量子化(約 40GB)で読み込む場合、PCIe Gen5 x16(約 64 GB/s)でも 1 秒前後の転送が走ります。FP16 なら 140GB 級になるので 2 秒以上かかります。
このコピーは推論中に常時走るわけではないので一見地味ですが、モデルの切り替えが多い使い方では効いてきます。複数モデルを切り替えながら使う実験や、KV キャッシュをまたぐような特殊な構成では、転送コストが体感の遅さに直結します。
Apple Silicon ではこの転送そのものが存在しません。CPU が LLM の前処理(トークナイズ)をしている横で、GPU が同じメモリ上の重みを読み始められます。「読み込みの速さ」「ロードからの応答速度」を体感で比べると、Mac の方が軽快に感じるのはこのためです。
帯域:NVIDIA が圧倒的に上
ただし、帯域そのものは NVIDIA が大差で勝ちます。
| 機材 | メモリ種別 | 帯域 |
|---|---|---|
| RTX 5090 | GDDR7 32GB | 1,792 GB/s |
| RTX PRO 6000 Blackwell | GDDR7 ECC 96GB | 1,800 GB/s |
| Mac Studio M3 Ultra | LPDDR5X 256GB Unified | 819 GB/s |
| Mac Studio M4 Max | LPDDR5X 128GB Unified | 546 GB/s |
| H100(参考) | HBM3 80GB | 3,350 GB/s |
LLM の推論は典型的なメモリ帯域律速のワークロードです。「重み全部を1トークンごとに読み直す」のが Transformer の基本動作なので、帯域がそのまま tok/s に効きます。RTX 5090 の 1,792 GB/s は M3 Ultra の 819 GB/s に対して約 2.2 倍、ここに推論速度の差がそのまま現れます。
容量:Apple が圧勝(70B FP16 を1台で動かせる)
帯域が NVIDIA 優位な一方、容量は完全に Apple のターンです。
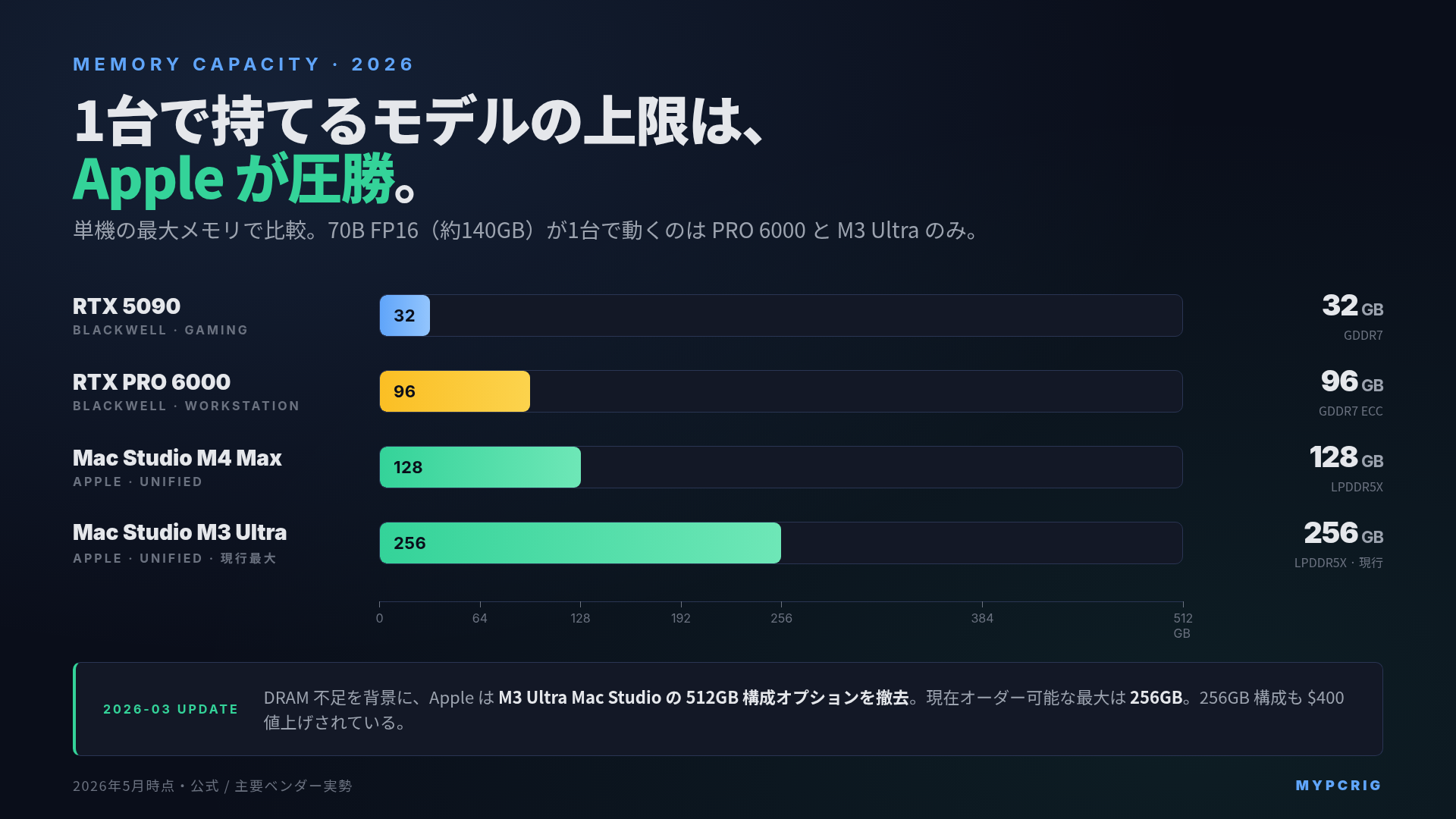
70B クラスのモデルを FP16 のまま動かすには約 140GB のメモリが必要です。1台で素直にこれをやれるのは、現実的には RTX PRO 6000(96GB だと FP16 はギリギリ無理、Q8 ならOK)と Mac Studio M3 Ultra(256GB なら 70B FP16 + KV キャッシュまで余裕)だけです。RTX 5090 の 32GB では 70B Q4 もギリギリで、KV キャッシュを長く持つと溢れます。
なお、ここに 2026年5月時点の補足が1つあります。M3 Ultra Mac Studio は発売当初(2025年3月)は最大 512GB の構成があり、これが「LLM 用 Mac の象徴」のように扱われていました。しかし 2026年3月、世界的な DRAM 不足を理由に Apple は 512GB オプションを撤去、現在オーダーできる最大は 256GB です。256GB 構成自体も $400 値上げされています。「512GB の Mac Studio が買える」という前提で記事を書いている英語ブログがまだ多いので、これから注文を検討する方はご注意ください。
中古市場(eBay 等)には 512GB の M3 Ultra Mac Studio がまだ流通しているので、本気で 192GB 超の構成を狙うなら中古ルートも選択肢に入ります。
Llama 3.3 70B の実測:tok/s で見るとどう違うか
Llama 3.3 70B(または 3.1 70B)を Q4_K_M で動かしたときの推論速度の目安は次のようになります。コミュニティ報告と各種ベンチマーク記事から拾った数字で、構成・コンテキスト長で揺れる前提です。
| 機材 | 70B Q4 推論 tok/s | 70B FP16 動作 |
|---|---|---|
| RTX 5090(32GB) | 20–30 tok/s | ✗(VRAM 不足) |
| RTX PRO 6000(96GB) | 30+ tok/s(推定) | ✗(FP16=140GB 必要) |
| Mac Studio M3 Ultra(256GB) | 10–15 tok/s | ✓ |
| Mac Studio M4 Max(128GB) | 8–15 tok/s | △(KV 込みで圧迫) |
体感としては、Mac の 10–15 tok/s は「人間が読む速度よりちょっと速い」程度で、対話には十分実用的です。一方、RTX 5090 の 20–30 tok/s は「画面を埋めていくのが目で追えないくらい速い」レンジで、長文生成や agent 的な反復ループでは差が大きく出ます。コードを LLM に書かせて待つような使い方では、5090 の速度が効きます。
70B FP16 を扱える点で M3 Ultra は依然唯一無二の存在ですが、Q4 で十分という割り切りができるなら、5090 の方が「速くて安い」ケースが多くなります。
学習・ファインチューニング:NVIDIA がまだ強いが、差は縮まっている
ここはまだ NVIDIA 優位です。CUDA + bitsandbytes + PEFT (LoRA / QLoRA) のエコシステムが圧倒的に成熟しており、論文の追試・公開コードの実行・新しい手法の検証は基本 CUDA 前提で動いています。Apple Silicon でも MLX(Apple 公式 ML フレームワーク)と llama.cpp の Metal バックエンドが Llama 3 系の LoRA に対応してきましたが、最新論文をすぐ動かしたいときは PyTorch + CUDA の方が摩擦が少ないのが現実です。
ただし、Apple Silicon 側の進歩は速いです。MLX-LM は Hugging Face モデルをほぼそのまま読めるようになり、QLoRA 相当の手法も使えます。「Mac だと学習はムリ」というのは2024年頃までの話で、2026年現在は「個人レベルの LoRA ファインチューニングなら Mac でも普通にできる」レベルにきました。バッチサイズを大きく取ってのフル学習やマルチノード分散学習はさすがに NVIDIA + データセンター GPU の世界で、個人ユーザーが日常的に踏み込むラインではありません。
電力・騒音・設置環境:Apple が圧倒的に静か
実用面で見落とされがちなのが電力と騒音です。
- RTX 5090:TGP 575W、ケースファン込みで実消費 700W 級。ブロワー音はオフィスでは音量的に厳しいラインで、夏場のエアコン無し部屋では明らかに発熱します。
- RTX PRO 6000 Blackwell:TGP 600W、ワークステーション向けクーラーで騒音は若干マシだが発熱量は同等。
- Mac Studio M3 Ultra:実消費 100–200W 程度、ファン音はアイドル時ほぼ無音、フル負荷でも控えめ。デスク上に置いてLLM を回しっぱなしにしても気にならない静かさです。
「居室で常時 LLM を動かしたい」「録音やビデオ会議の横で推論を走らせたい」用途では、この差は決定的です。VRAM がメモリ界のスポーツカーだとすれば、Unified Memory は荷物がたくさん積めて燃費の良いミニバン、というのが私の中の比喩イメージで、置き場所と用途で素直に分かれます。
用途別の判断軸 4 パターン
ここまでをまとめると、選び方は次の4つに収束します。
パターン1:1台で 70B 以上の超大型モデルを丸ごと持ちたい / モデルサイズ最優先 → Mac Studio M3 Ultra(256GB 構成、できれば中古で 512GB 構成を狙う)。70B FP16 や、Q8 の 100B 級を1台で扱える唯一現実的な選択肢です。
パターン2:70B Q4 を高速推論したい / コスパ重視 / 32GB あれば足りる → RTX 5090。20–30 tok/s の推論速度は agent ワークロードや長文生成で効きます。Mac Studio の半額〜2/3 で組める点も大きい。
パターン3:学習・ファインチューニング中心 / バッチ処理多用 / 最新論文を追う → RTX PRO 6000 単機、または RTX 5090 複数枚。CUDA エコシステム前提のワークフローではこれ以外の選択肢が現実的に存在しません。法人・研究室向け。
パターン4:静音・省電力・オフィス据え置き / インテリアと両立 → Mac Studio(M4 Max 128GB か M3 Ultra 256GB)。575W のグラボ騒音と発熱を居室に持ち込まずに済む価値は、毎日触る道具では大きいです。
2026年後半に向けたメモ
最後に1点、購入タイミングの話です。M4 Ultra は開発がキャンセルされたとされており、Apple は次のフラッグシップとして M5 Ultra を 2026年10月前後に出すと噂されています。「今すぐ Mac で 70B を回したい」のでなければ、M5 Ultra の発表を待つ判断もアリです。逆に NVIDIA 側は Blackwell 世代がしばらく続く見込みなので、5090 / PRO 6000 の購入タイミングはあまり気にしなくて良いと思います。
Mac Studio M3 Ultra を Apple公式サイトで見る
VRAM 側の数値の決まり方そのものについては「VRAMとは何か。ローカルLLM推論で必要な量の決まり方 2026年版」で詳しく扱っています。GPU を選ぶ手前の段階でこの記事に戻ってきていただけると、必要量の見積もりが楽になります。
NVIDIA 側でどのカードを選ぶかについては「RTX 5090 vs 4090 vs PRO 6000 — AI用途で選ぶGPU 2026」、PC 全体構成の最低スペックについては「ローカルLLMを動かすPCの最低スペック 2026年版」がそれぞれ続編として読めます。
あなたに合うPCを診断する
用途や予算をもう少し細かく入力すると、3つの候補構成を提案します。
→ 診断スタート
関連記事
よくある質問
- MacBook Pro と RTX 搭載 PC、ローカルLLM ではどちらが有利?
- 結論は用途で割れます。容量を取るなら MacBook Pro(Unified Memory なので搭載メモリの大半をモデルに割ける)、tok/sec の生成速度を取るなら RTX 搭載機(GDDR7 の帯域が圧倒的に上)です。本記事の構造比較のとおり、Apple Silicon は CPU と GPU が同じメモリプールを共有する設計で、PCIe コピー税が発生しない代わりに帯域は控えめ。NVIDIA は GPU 専用の VRAM で帯域が桁違いに広い代わり、容量はチップのパッケージ上限で頭打ちです。70B 級を FP16 のまま 1台で扱いたいなら Mac 系、Q4 で十分かつ高速生成したいなら RTX 系、というのが素直な切り分けになります。ノート PC 文脈での選び方は [ローカルLLMを動かすノートPCガイド 2026年版](/blog/local-llm-ai-laptop-guide-2026/) で機種別にまとめています。
- Mac Studio M3 Ultra 512GB はもう買えませんか?
- 2026年5月時点で Apple 公式からの新規オーダーは不可です。世界的な DRAM 不足を理由に Apple は 2026年3月に 512GB オプションを撤去しており、現在オーダーできる最大は 256GB 構成です。256GB 構成自体も $400 値上げされています。一方、中古市場(eBay 等)には発売当初(2025年3月)に出荷された 512GB の M3 Ultra Mac Studio がまだ流通しているので、本気で 192GB 超の構成を狙うなら中古ルートが選択肢になります。
- 70B モデルを FP16 のまま 1台で動かせるのはどの機材?
- 現実的には Mac Studio M3 Ultra 256GB 構成だけです。70B クラスのモデルを FP16 のまま動かすには約 140GB のメモリが必要で、RTX PRO 6000 Blackwell(96GB)でも FP16 はギリギリ収まりません(Q8 なら OK)。RTX 5090 の 32GB では 70B Q4 でもギリギリで KV キャッシュを長く持つと溢れます。Mac Studio M3 Ultra(256GB)なら 70B FP16 + 長めの KV キャッシュまで余裕で扱えるため、「1台で 70B FP16」を素直にやれる唯一の選択肢になります。
- RTX 5090 と Mac Studio M3 Ultra で 70B Q4 の tok/sec はどれだけ違う?
- 本記事の実測まとめのとおり、RTX 5090 が 20〜30 tok/s、Mac Studio M3 Ultra が 10〜15 tok/s で、約 2 倍の速度差があります。これは GDDR7(1,792 GB/s)と LPDDR5X(819 GB/s)の帯域比とほぼ一致します。LLM の推論は典型的なメモリ帯域律速のワークロード(重み全体を 1 トークンごとに読み直す)なので、帯域差がそのまま tok/sec の差に現れる構造です。Mac の 10〜15 tok/s は対話用途には十分実用的ですが、agent ループのような反復生成では RTX 5090 の速度が効きます。
- Unified Memory と VRAM、結局どちらを選べばいい?
- 用途で 4 つに分かれます。①最大モデル(70B FP16 / 100B Q8 級)を 1 台に積みたいなら Mac Studio M3 Ultra。②70B Q4 を高速推論したいなら RTX 5090。③学習・ファインチューニング中心・最新論文を追うなら RTX PRO 6000 単機または RTX 5090 複数枚(CUDA + bitsandbytes + PEFT のエコシステムが圧倒的)。④静音・省電力・オフィス据え置き / インテリアと両立するなら Mac Studio(M4 Max 128GB or M3 Ultra 256GB)。本記事の「用途別の判断軸 4 パターン」の章で詳細を扱っています。