Mac Studio でローカルLLM を動かす完全ガイド 2026年版:M4 Max / M3 Ultra の Unified Memory 容量別に何が動くか
Mac Studio M4 Max / M3 Ultra でローカルLLM を動かす実用ガイド 2026年版。Unified Memory 64GB / 96GB / 128GB / 192GB / 256GB / 512GB の各構成で何B モデルまで動くかを整理し、llama.cpp / Ollama / MLX の使い分けと量子化選択を解説します。
- #Mac Studio
- #ローカルLLM
- #Apple Silicon
- #M4 Max
- #M3 Ultra
- #Unified Memory
- #MLX
- #Ollama
- #DeepSeek R1
- #Llama 3.3
本記事は Amazon.co.jp および各販売店のアフィリエイトリンクを含む場合があります。推奨は性能・コスパ・実機ベンチマーク基準で編集判断しており、提供記事は受け付けていません。詳細は プライバシーポリシー をご覧ください。
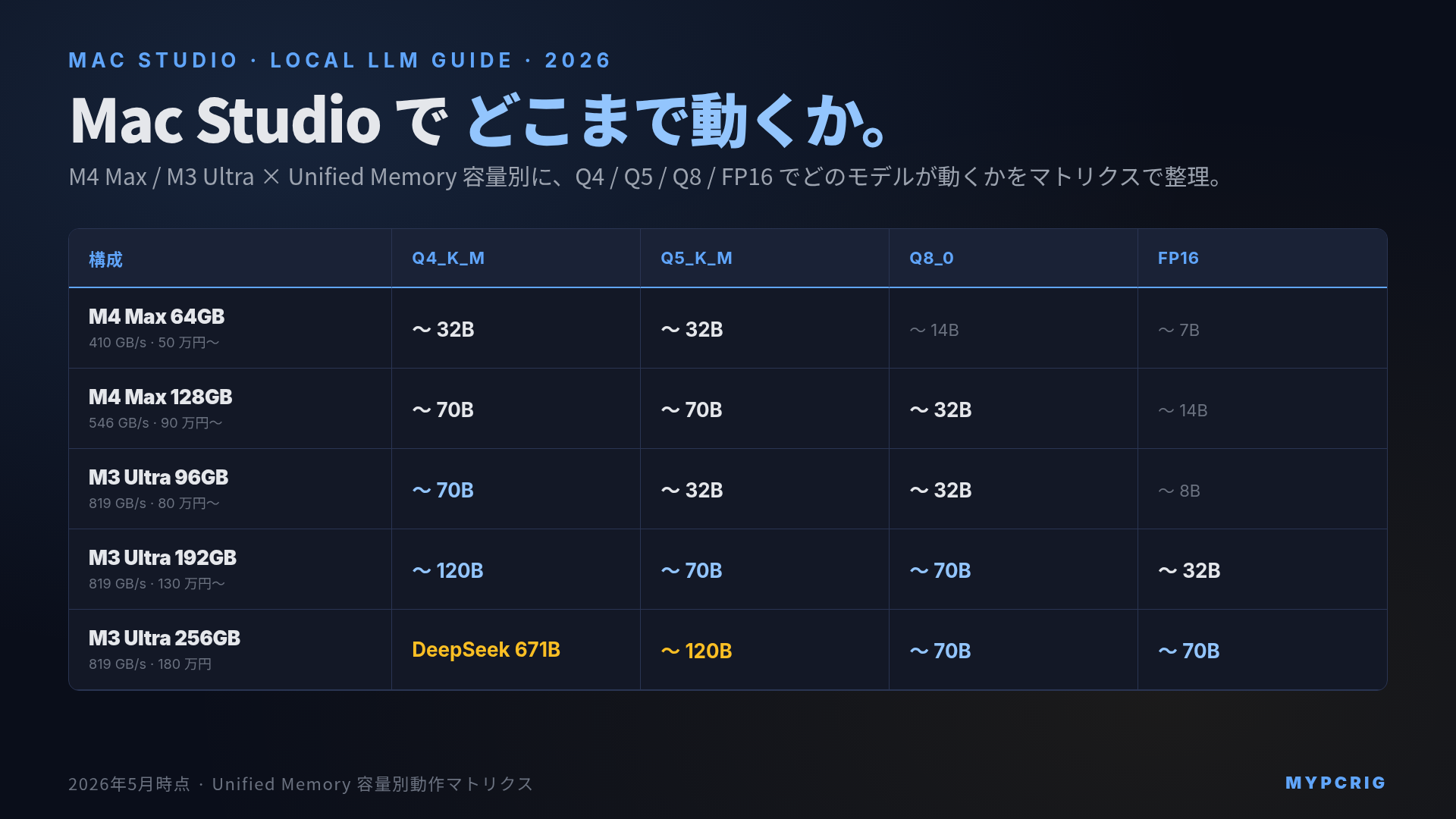
結論:Mac Studio でローカル LLM を動かすなら、まず M4 Max 64GB を「30〜32B が量子化で快適に回る最小ライン」と覚えてください。70B クラスを Q4 で 8〜15 tok/s 級の実用速度にしたいなら M4 Max 128GB か M3 Ultra 96GB、Llama 3.3 70B を FP16 で扱う研究用途や DeepSeek R1 671B クラスを 1 台に押し込みたいなら M3 Ultra 256GB 以上、それ以下は構成的に意味が薄いです。
「Mac Studio でローカル LLM はどこまで動きますか」は、Mac Studio の新規購入相談で 2026 年に最も多くなった質問です。M3 Ultra と M4 Max の二段構成、しかも Unified Memory の選択肢が 64GB / 96GB / 128GB / 192GB / 256GB(M3 Ultra のみ)と幅広く、組み合わせの数だけで判断が止まりがちです。この記事では、Mac Studio に絞って Unified Memory 容量別にどのモデルがどの量子化で動くか をマトリクスで整理し、ランタイム選択(llama.cpp / Ollama / MLX / LM Studio)と量子化(Q4_K_M / Q5_K_M / Q8_0 / FP16)の判断軸まで整理します。
Mac Studio と MacBook Pro を含む「Claude Code 用途」での選び方は別記事「Mac で Claude Code とローカルLLM を動かす Apple Silicon 構成 2026年版」、Mac Studio vs NVIDIA dGPU の比較ベンチマークは「Mac Studio M3 Ultra vs RTX 5090 ローカルLLM 推論ベンチマーク 2026年版」を合わせて参照してください。本記事は「Mac Studio に絞って、買う前にどの容量を選ぶか」という購買判断のガイドです。
2026年5月時点の Mac Studio ラインナップ
まず現行ラインを整理します。Apple は 2025 年に M3 Ultra と M4 Max の 2 チップで Mac Studio を構成しており、2026 年 5 月時点でも継続しています。
| チップ | Unified Memory 選択肢 | メモリ帯域 | 価格目安(税込) |
|---|---|---|---|
| M4 Max | 36 / 48 / 64 / 128 GB | 410〜546 GB/s | 36〜90 万円 |
| M3 Ultra | 96 / 192 / 256 GB | 約 800 GB/s | 80〜180 万円 |
512GB オプションは 2026 年 4 月に静かに撤去され、256GB の価格も上方修正されました。DRAM 価格の高騰を背景にした調整と見られています。M5 Ultra の Mac Studio は 2026 年後半に予定されており、メモリ帯域 1,200 GB/s 超・最大 256GB という噂が流れていますが、本記事ではまだ流通している M3 Ultra / M4 Max を前提に判断します。
ローカル LLM 用途で見ると、M4 Max は「中規模モデルを安定して回す」、M3 Ultra は「70B 以上を 1 台で完結させる」という役割分担になっており、両者の中間(96GB / 128GB あたり)が最も悩ましいゾーンです。
Unified Memory 容量別:何B モデルがどこまで動くか
macOS は Unified Memory の最大 75% を GPU 側(≒ LLM 推論側)にデフォルトで割り当てます。Terminal から sudo sysctl iogpu.wired_limit_mb を叩いて引き上げれば 90% 級まで GPU 用に確保できますが、その分 OS とアプリの動作領域が圧迫されるので、まずデフォルト 75% で見ます。
下表は各構成で「実用速度(5 tok/s 以上、Swap に落ちない)」で動かせるモデル × 量子化の上限目安です。
| 構成 | GPU 用枠(≒75%) | Q4_K_M 上限 | Q5_K_M 上限 | Q8_0 上限 | FP16 上限 |
|---|---|---|---|---|---|
| M4 Max 64GB | 約 48GB | 〜 32B | 〜 32B | 〜 14B | 〜 7B |
| M4 Max 128GB | 約 96GB | 〜 70B | 〜 70B | 〜 32B | 〜 14B |
| M3 Ultra 96GB | 約 72GB | 〜 70B | 〜 32B | 〜 32B | 〜 8B |
| M3 Ultra 192GB | 約 144GB | 〜 120B | 〜 70B | 〜 70B | 〜 32B |
| M3 Ultra 256GB | 約 192GB | 〜 235B (MoE) | 〜 120B | 〜 70B | 〜 70B |
モデルファイルのサイズだけを見て買うと必ず外します。推論時には KV キャッシュ(コンテキスト長に比例)と推論バッファが追加で必要で、Q4_K_M の Llama 3.3 70B(実ファイル 42GB)を 32k context で回すと実効 55〜60GB、128k context にすると 70GB 近くまで膨らみます。「ファイルサイズ + 30〜50%」を目安に余裕を持って構成してください。
ベンチの実測:構成別の推論速度
2026 年 5 月時点で公開されている主要ベンチを Mac Studio に絞って整理します。MLX(Apple 純正)と llama.cpp(Ollama / LM Studio が内部で使う)の 2 系統で測った値です。
| 構成 | モデル / 量子化 | ランタイム | 推論速度(短コンテキスト) |
|---|---|---|---|
| M4 Max 64GB | Qwen3 14B MLX | MLX | 約 24 tok/s |
| M4 Max 64GB | Qwen2.5 32B Q4_K_M | Ollama | 約 11 tok/s |
| M4 Max 128GB | Llama 3.3 70B Q4_K_M | Ollama | 約 8.5 tok/s |
| M4 Max 128GB | Llama 3.3 70B MLX 4bit | MLX | 約 11 tok/s |
| M3 Ultra 96GB | Llama 3.3 70B Q4_K_M | Ollama | 約 13 tok/s |
| M3 Ultra 192GB | Llama 3.3 70B FP16 | MLX | 約 12 tok/s |
| M3 Ultra 256GB | DeepSeek R1 671B Q4 (MoE) | llama.cpp | 約 17〜18 tok/s |
| M3 Ultra 256GB | Qwen3 235B MoE 4bit | MLX | 約 30〜40 tok/s |
人間が読み流す速度はおおよそ 8〜10 tok/s なので、Q4 70B を 10 tok/s 級で常用したい人は M4 Max 128GB か M3 Ultra 96GB が下限になります。M3 Ultra 256GB で DeepSeek R1 671B が 17〜18 tok/s 出るのは、MoE(Mixture-of-Experts)で 1 トークンあたり実際にアクティブになるパラメータが 37B 程度に減ることが効いています。MoE モデルが Mac Studio 大容量機の主役用途です。
llama.cpp 系より MLX が 10〜25% 速いのは、Apple Silicon の AMX 命令や Metal 上の最適化が MLX に集約されているためです。同じモデルでも MLX 版(Hugging Face の mlx-community org にプリビルドあり)を選ぶだけで体感が変わります。
VRAM 割当の挙動:macOS の 75% ルールと引き上げ方
Mac Studio で「128GB あるのに 70B FP16 が乗らない」と詰まるケースの多くは、VRAM 割当の上限が原因です。デフォルトでは Unified Memory の 75% までしか GPU が掴めません。
# 現在の上限を確認(バイト単位)
sysctl iogpu.wired_limit_mb
# 引き上げ例:128GB 機で 110GB(112640 MB)まで GPU に許可
sudo sysctl iogpu.wired_limit_mb=112640この設定は再起動で消えます。常用するなら /etc/sysctl.conf に追記するか、ログイン時の LaunchAgent で叩く運用が一般的です。M3 Ultra 512GB(流通在庫)で DeepSeek R1 671B を動かす場合は、iogpu.wired_limit_mb=458752(448GB)まで上げる例が報告されています。
ただし GPU 枠を上げすぎると OS とアプリ側が窮屈になり、Swap が走り始めると推論速度が一気に崩壊します。実測で M4 Pro 24GB に 32B Q8 を押し込んだケースでは、Swap 突入で 10 tok/s が 0.28 tok/s(理論の 1/35)まで落ちました。Mac Studio でも 90% 超のアグレッシブ割当は、必ず実運用テストをしてから常用してください。
ランタイム選択:llama.cpp / Ollama / LM Studio / MLX
Mac Studio で実用的に使える 4 つのランタイムを役割で整理します。
| ランタイム | 速度 | セットアップ | GUI | 対応モデル数 |
|---|---|---|---|---|
| MLX (mlx-lm / mlx-vlm) | ◎(最速) | △(pip) | × | ○(増加中) |
| llama.cpp(直叩き) | ○ | △(make) | × | ◎(最多) |
| Ollama | ○ | ◎(1コマンド) | ×(CLI) | ◎(公式 + Hub) |
| LM Studio | ○〜◎ | ◎(GUI) | ◎ | ◎(MLX も対応) |
2026 年 5 月時点の推奨はシンプルで、「速度を最大化するなら MLX、楽さなら Ollama か LM Studio、両方欲しいなら LM Studio + MLX バックエンド」です。 Ollama も 2025 年後半に MLX バックエンドのプレビュー対応を入れたので、Ollama を使いつつ MLX の速度メリットを取る選択肢も実用ラインに入ってきました。
具体的な使い分けは、研究・最大速度が必要なら MLX を直接叩く(mlx_lm.generate ...)、日常運用なら Ollama(ollama run llama3.3:70b で即実行)、GUI で家族や同僚に触ってもらうなら LM Studio、というのが標準的な構成です。
量子化選択:Q4_K_M / Q5_K_M / Q8_0 / FP16 の体感差
Mac Studio で意外と差が出るのが量子化選択です。GPU 帯域が NVIDIA に比べて控えめ(M4 Max 546GB/s、M3 Ultra 800GB/s、対する RTX 5090 は GDDR7 で約 1,792GB/s)なので、量子化を細かくしても帯域律速で速度が頭打ちになりやすい一方、品質低下は確実に効いてきます。
| 量子化 | サイズ目安(70B) | 速度(M4 Max 128GB) | 品質 | 推奨用途 |
|---|---|---|---|---|
| Q4_K_M | 42 GB | 約 8.5 tok/s | △〜○ | 常用、コード生成、要約 |
| Q5_K_M | 50 GB | 約 7.5 tok/s | ○ | 翻訳、構造化出力 |
| Q8_0 | 73 GB | 載らない | ◎ | 研究、品質重視 |
| FP16 | 140 GB | 載らない | ◎ | 研究(M3 Ultra 192GB 以上) |
Mac Studio では、「常用なら Q4_K_M で十分、構造化出力やコード生成の精度が問題になったら Q5_K_M に上げる」「品質をきっちり評価するときだけ M3 Ultra で Q8_0 / FP16 を回す」 の三段階で運用するのが現実解です。Q3 以下は品質低下が体感で分かるレベルなので、メモリ節約で Q3 を選ぶより 1 つ下のサイズ(70B → 32B)の Q4 を取るほうが結果が安定します。
用途別の推奨構成
ここまでを 3 つのプリセットに整理します。
入門:30B 級までを安定して回す
| 項目 | 構成 |
|---|---|
| 機種 | Mac Studio M4 Max |
| メモリ | 64 GB |
| 用途 | Qwen3 14B / Qwen2.5 32B Q4 を 11〜24 tok/s で運用 |
| 価格目安 | 50〜55 万円 |
ローカル LLM を本格的に触る人の最小構成です。70B クラスは現実的に厳しいので、「30B 級で十分」が事前に確定している人向けです。M4 Max 64GB は MLX の最適化が効いて 32B クラスでの体感が良好で、Claude Code を主、ローカルを補助で使うハイブリッド派にもよく合います。
実用:70B を Q4 で常用する
| 項目 | 構成 |
|---|---|
| 機種 | Mac Studio M4 Max 128GB または M3 Ultra 96GB |
| メモリ | 128 GB / 96 GB |
| 用途 | Llama 3.3 70B Q4 を 8〜13 tok/s で日常運用 |
| 価格目安 | 80〜95 万円 |
「Mac Studio × ローカル LLM」で迷ったら、まずこのラインを基準にしてください。M4 Max 128GB は GPU 枠が約 96GB と Q5 70B まで実用域、M3 Ultra 96GB は GPU 帯域 800GB/s で同じ Q4 70B が 1.5 倍速で回ります。価格が同じなら M3 Ultra 96GB を取るほうがローカル LLM 用途では合理的で、M4 Max 128GB はメモリ容量で勝負したい人向けです。
研究:70B FP16 / 100B+ MoE を 1 台で
| 項目 | 構成 |
|---|---|
| 機種 | Mac Studio M3 Ultra |
| メモリ | 192 / 256 GB |
| 用途 | Llama 3.3 70B FP16、Qwen3 235B MoE、DeepSeek R1 671B Q4 |
| 価格目安 | 130〜180 万円 |
M3 Ultra 192GB 以上は MoE モデル時代の Mac Studio の強みが活きる 構成です。Qwen3 235B MoE 4bit が 30〜40 tok/s、DeepSeek R1 671B Q4 が 17〜18 tok/s で動くマシンは、2026 年 5 月時点で個人レベルの予算では他にほぼ選択肢がありません。NVIDIA で 671B を Q4 で回そうとすると H100 80GB を 4〜5 枚 + InfiniBand という構成になり、桁が変わります。「研究で 100B+ クラスを 1 台で完結させたい」が確定している人だけの構成です。
結局どの構成を買うべきか:用途別チャート
最後に、迷ったときの判断フローです。
| やりたいこと | 推奨構成 |
|---|---|
| Claude Code 主体、ローカルは補助 | M4 Max 64GB |
| 30B 級を常用、70B は時々 | M4 Max 64GB(妥協)or M3 Ultra 96GB |
| 70B Q4 を常用 | M3 Ultra 96GB(コスパ最良) |
| 70B Q5 / 32B Q8 を常用 | M4 Max 128GB |
| 70B FP16 で精度評価したい | M3 Ultra 192GB |
| MoE 100B+ や DeepSeek R1 を動かしたい | M3 Ultra 256GB |
| 学習・ファインチューニング主体 | Mac Studio ではなく NVIDIA dGPU 機 |
最後の行は重要で、Mac Studio は推論には強いが学習・LoRA ファインチューニングは NVIDIA に大きく劣ります。MLX も学習対応は進んでいますが、PyTorch + CUDA エコシステムの厚みには現状追いついていません。学習主体なら最初から RTX 5090 や Pro 6000 系を検討するのが筋です。Unified Memory と NVIDIA VRAM の構造的な違いは「Apple Silicon の Unified Memory と NVIDIA VRAM、ローカルLLM では何が違うのか 2026年版」で詳しく整理しています。
入手先・関連商品
当サイトは Amazon.co.jp アソシエイト・プログラムに参加予定です。下記リンク経由で購入された場合、紹介料を受け取ることがあります。読者の負担は増えません。リンクは記事評価とは独立しており、編集判断には影響しません。
Mac Studio 本体(用途別 3 構成)
- Mac Studio M4 Max 64GB を Amazon.co.jp で見る — 30B 級を Q4 で安定運用する入門ライン
- Mac Studio M3 Ultra 96GB を Amazon.co.jp で見る — 70B Q4 常用のコスパ最良ライン(本記事の推奨中心)
- Mac Studio M3 Ultra 256GB を Amazon.co.jp で見る — DeepSeek R1 671B クラスを動かす研究用途
あなたに合うPCを診断する
用途や予算をもう少し細かく入力すると、3つの候補構成を提案します。
→ 診断スタート
関連記事
- Mac で Claude Code とローカルLLM を動かす Apple Silicon 構成 2026年版 — Mac Studio + MacBook Pro を横断した Claude Code 用途の選び方
- Mac Studio M3 Ultra vs RTX 5090 ローカルLLM 推論ベンチマーク 2026年版 — Mac Studio と NVIDIA dGPU を実測ベンチで比較
- Apple Silicon の Unified Memory と NVIDIA VRAM、ローカルLLM では何が違うのか 2026年版 — Unified Memory と VRAM の構造的な違い
- Mac mini vs Mac Studio 2026年版:据え置き Mac の選び方 — 据え置き Mac の用途別比較