メモリ帯域幅(GB/s)がローカルLLMの tok/sec を決める仕組み 2026年版:VRAM容量より「帯域」を見るべき理由と GPU・Apple・Strix Halo の実数値
ローカルLLMの生成速度(tok/s)はGPU性能やTOPSではなく、ほぼメモリ帯域幅(GB/s)で決まります。tok/s(tok/sec)の読み方から、なぜ帯域がトークン生成を律速するのかの仕組み、RTX 5090・Mac M4 Max/M3 Ultra・Strix Halo・DDR5の実帯域まで並べ、容量と帯域のどちらを優先すべきかの判断軸を示します。
- #メモリ帯域
- #ローカルLLM
- #tok/sec
- #Unified Memory
- #VRAM
- #GPU
- #Strix Halo
- #Apple Silicon
本記事は Amazon.co.jp および各販売店のアフィリエイトリンクを含む場合があります。推奨は性能・コスパ・実機ベンチマーク基準で編集判断しており、提供記事は受け付けていません。詳細は プライバシーポリシー をご覧ください。
結論:ローカルLLMのトークン生成速度(tok/sec)は、GPUの演算性能やTOPSではなく、ほぼメモリ帯域幅(GB/s)で決まります。理由は、1トークン生成するたびにモデルの全重みをメモリから読み出すから。生成速度の理論上限は「メモリ帯域 ÷ モデルサイズ」で計算でき、実効はその60〜80%程度です。スペックを見るときは、VRAM容量で『動くかどうか』を、メモリ帯域で『動いた後の速さ』を判断する。この2段構えが正解です。容量は門番、帯域は速度。
「VRAMが多ければローカルLLMは速い」とよく言われますが、これは半分正しくて半分間違いです。VRAM容量が決めるのは「そのモデルが載るかどうか」であって、「載った後どれだけ速いか」ではありません。後者を決めるのはメモリ帯域幅(GB/s)です。
この区別を知らないと、買い物で事故ります。たとえば「128GBもあるのに70Bが遅い」と落胆したり、逆に「32GBしかないGPUが爆速」に驚いたり。私はこの記事で、なぜ帯域がトークン生成速度を支配するのかを仕組みから説明し、主要ハードの実帯域を一枚に並べて、容量と帯域のどちらを優先すべきかの判断軸を渡します。一度わかると、スペック表の見え方が変わります。
tok/s(tok/sec)とは何かを30秒で
本題に入る前に、この記事で繰り返し出てくる tok/s(tok/sec) という単位だけ先に押さえておきます。tok/s は tokens per second=1秒間に生成できるトークン数 のことで、「文章がどれだけサクサク出てくるか」の速度指標です。日本語ではおおよそ1トークン=1〜2文字程度に対応します。
ポイントは、この tok/s が指すのは後述するトークン生成(decode)フェーズの速度だということ。そして本記事の核心は、この値が「メモリ帯域 ÷ モデルサイズ」でほぼ決まる、という1点です。だから tok/s を上げたければ、帯域の高いハードを選ぶか、モデルを小さくするかのどちらか。GPUの演算性能やTOPSをいくら上げても tok/s はほとんど変わりません。この理由を、これから仕組みから説明します。なお、ここで言う「モデルサイズ」がそもそも何で決まるか(7B/70Bといったパラメータ数)は「ローカルLLMのパラメータ数 7B / 13B / 70B / 405B とは何か」で扱っています。
なぜ「帯域」が速度を決めるのか:1トークン=全重み読み出し
まず仕組みです。大規模言語モデルがテキストを生成するとき、内部では大きく2つのフェーズが走ります。
- prefill(プロンプト処理):入力された文章を一気に読み込んで内部状態を作る。ここは行列演算が主役で、GPUの演算性能(FLOPS / TOPS)が効く
- decode(トークン生成):1トークンずつ次の単語を生成していく。ここでは毎回モデルの全パラメータ(重み)をメモリから読み出す
問題は2つ目の decode です。70Bモデルを4bit量子化(Q4)すると約40GBの重みになります。この40GBを、1トークン生成するたびに丸ごとメモリから読み込む必要があります。つまり、1秒間に何トークン出せるかは「1秒間にメモリから何GB読めるか」=メモリ帯域で頭打ちになる、というわけです。
ここで効かないのがGPUの演算性能です。decode の計算自体は軽く、ボトルネックは「重みをメモリから運んでくる時間」。いくら演算ユニットが速くても、データが届かなければ手持ち無沙汰になります。トラックの荷台がどれだけ大きく、エンジンがどれだけ速くても、荷物を積む道幅(帯域)が狭ければ運べる量は道幅で決まります。ローカルLLMの decode は、まさにこの状態です。
理論上限の計算式:帯域 ÷ モデルサイズ
仕組みがわかると、生成速度の理論上限がざっくり計算できます。
理論 tok/sec ≒ メモリ帯域(GB/s) ÷ モデルサイズ(GB)
実例を出します。メモリ帯域800GB/sのマシンで、40GBのモデル(70B Q4相当)を動かす場合:
- 理論上限 = 800 ÷ 40 = 20 tok/s
- 実効値 = 理論の60〜80% = 12〜16 tok/s
実効が理論を下回るのは、KVキャッシュの読み書き、メモリアクセスの非効率、ソフトウェアのオーバーヘッドなどがあるからです。それでも「帯域 ÷ サイズ」で出した理論値は、実測のだいたいの目安として驚くほどよく当たります。
この式から2つの重要な帰結が出ます。
- モデルが小さいほど速い:8B Q4(約4.6GB)なら 800 ÷ 4.6 ≒ 174 tok/s が理論上限。小型モデルが爆速なのはこのため
- 帯域が高いほど速い:同じ40GBモデルでも、帯域1,792GB/s(RTX 5090)なら理論44 tok/s、帯域215GB/s(Strix Halo)なら理論5.4 tok/s
「同じモデルなのにハードで速度が桁違い」の正体は、この帯域差です。
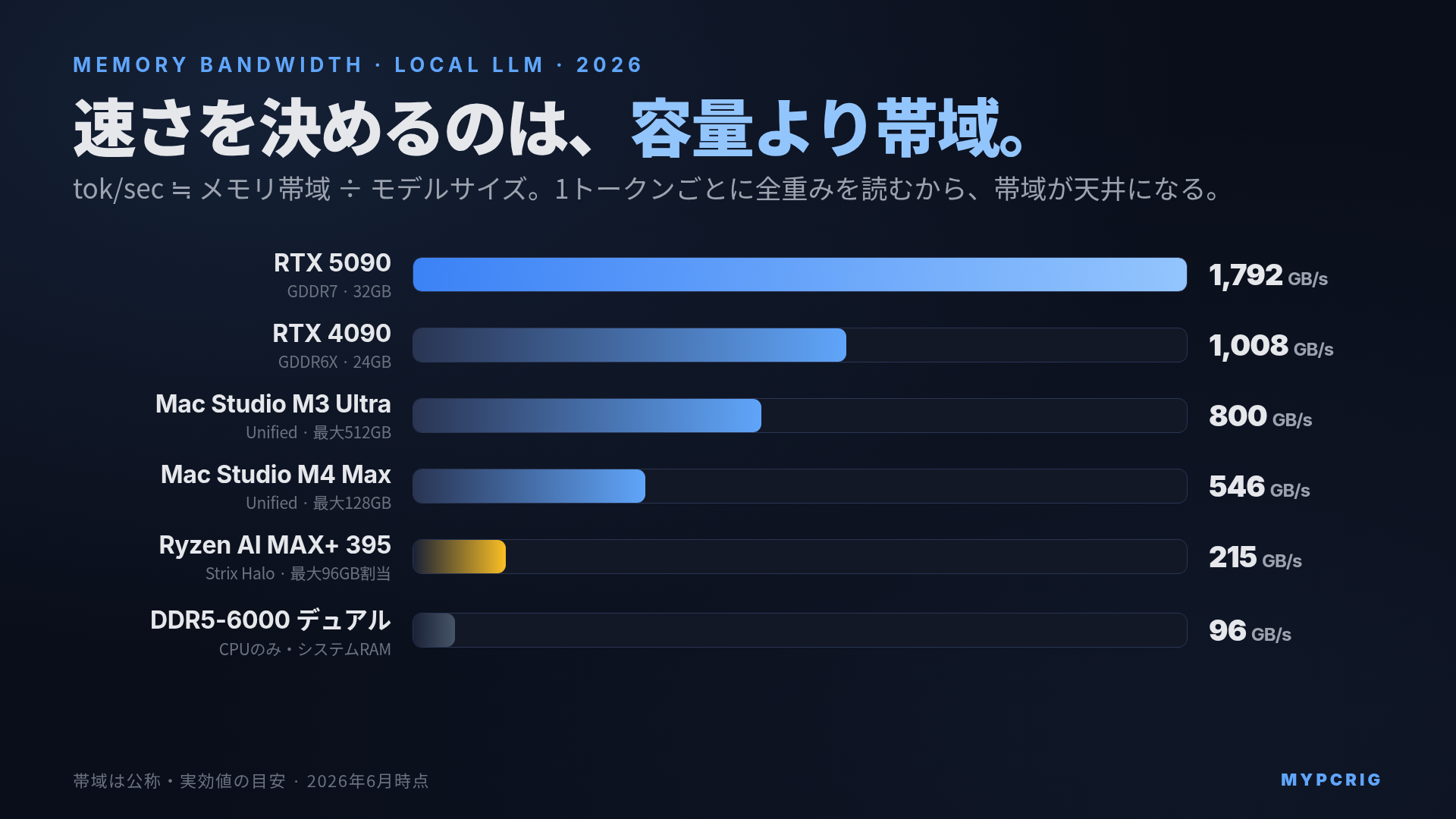
主要ハードの実メモリ帯域(2026年版・一枚表)
では実際のハードはどれくらいの帯域を持つのか。ローカルLLMで使われる主要な選択肢を並べます。
| ハード | メモリ帯域 | メモリ種別 | 利用可能容量 |
|---|---|---|---|
| RTX 5090 | 約1,792 GB/s | GDDR7 | 32GB |
| RTX 4090 | 約1,008 GB/s | GDDR6X | 24GB |
| Mac Studio M3 Ultra | 約800 GB/s | LPDDR5X(Unified) | 最大512GB |
| Mac Studio M4 Max | 約546 GB/s | LPDDR5X(Unified) | 最大128GB |
| Ryzen AI MAX+ 395(Strix Halo) | 約215〜256 GB/s | LPDDR5X(Unified) | 最大96GBをVRAM割当 |
| DDR5-6000 デュアルチャネル(CPUのみ) | 約96 GB/s | DDR5(システムRAM) | 容量次第 |
この表が、ローカルLLMの速度序列をほぼそのまま表しています。RTX 5090 が最速なのは演算が速いからではなく、帯域が群を抜いて高いから。逆にCPU+システムRAMだけでLLMを動かすと絶望的に遅いのは、DDR5デュアルチャネルの帯域が約96GB/sしかないからです。GPUやUnified Memoryと比べて1桁狭い道幅では、大きなモデルの重みを運びきれません。
各方式の帯域とアーキテクチャの違い、つまりなぜUnified MemoryとGDDRで設計思想が違うのかは「Apple Silicon の Unified Memory と NVIDIA VRAM、ローカルLLM では何が違うのか 2026年版」で掘り下げています。
容量 vs 帯域:門番と速度、優先順位の決め方
ここまでで「帯域=速度」はわかりました。ではVRAM容量は何のためにあるのか。容量と帯域は役割が違います。
| 観点 | VRAM/メモリ容量 | メモリ帯域 |
|---|---|---|
| 決めること | そのモデルが動くか動かないか | 動いた後の速さ |
| たとえると | 入店できる人数(門番) | 接客のスピード |
| 足りないと | モデルがロードできず起動すらしない | ロードはできるがもっさり遅い |
判断の順序はこうです。
- まず容量で「動くか」を確保する:動かしたいモデルが載らなければ、帯域がいくら高くても無意味。32GBのRTX 5090は帯域最強でも、70B Q8(約70GB)は物理的に載らないので動かせない
- 次に帯域で「速さ」を取る:載ることが確定したら、帯域が高いほど快適
具体例で整理します。70Bクラス(Q4、約40GB)を動かしたい場合:
- RTX 5090(32GB):容量不足で70B Q4はそのままでは載らない(門番で弾かれる)。複数枚や量子化を詰めれば別だが、単体では不可
- Strix Halo(128GB→96GB割当):容量はクリア(門番OK)。ただし帯域215GB/sなので速度は5〜8 tok/s と控えめ
- Mac Studio M3 Ultra(最大512GB):容量も帯域(800GB/s)も余裕。速度・容量の両取り
つまり「70Bが動くStrix Halo」と「帯域の高いMac/dGPU」は、どちらも70Bを扱えますが体感が違う。Strix Haloは「動くけどゆっくり」、MacやハイエンドdGPUは「動いてしかも速い」。同じ「70B対応」という看板でも、中身は別物です。
よくある勘違いトップ3
帯域の理解が浅いと陥りがちな誤解を、まとめて潰しておきます。
- 「TOPSが高い=LLMが速い」:TOPSはNPU/GPUの演算性能の指標で、decode(生成)にはほぼ効きません。NPU 50 TOPSをうたうチップでも、帯域が狭ければ生成は遅い。TOPSが効くのは prefill や画像生成など演算律速の処理です
- 「VRAMが多い=速い」:容量は門番であって速度計ではありません。128GBあっても帯域が低ければ生成は遅い
- 「prompt processing の数字=生成速度」:海外ベンチで「500〜800 tok/s」のような数字を見たら、たいてい prompt processing(prefill)の値です。あなたが体感する「文章がダラダラ出てくる速さ」はトークン生成(decode)の数字(多くは1桁〜数十 tok/s)のほうです。ここを混同すると期待値が壊れます
特に3つ目は製品レビューでも事故が多いポイントです。ベンチ数値を見るときは「これは pp(prefill)か tg(decode)か」を必ず確認してください。
まとめ:スペック表は「容量で動くか、帯域で速いか」の2段で読む
ローカルLLM向けにハードを選ぶときの読み方を、最後に1行で。
容量で『そのモデルが動くか』を確認し、帯域で『どれだけ速いか』を見積もる。
この2段構えさえ身につければ、スペック表の数字に振り回されなくなります。「128GBもあるのに遅い」は帯域を見れば予測できたし、「32GBなのに爆速」も帯域を見れば当然でした。VRAM容量の大きさに目を奪われがちですが、生成速度を決めているのは静かに帯域です。
VRAM容量そのものの決め方(どのモデルにどれだけ要るか)は「VRAMとは何か。ローカルLLM推論で必要な量の決まり方 2026年版」、AMD Strix Halo が大容量を共有メモリで実現する仕組みは「AMD Strix Halo の Unified Memory とは 2026年版」で扱っています。容量と帯域、両輪で理解すると機種選びの解像度が一段上がります。
ハードを買い替えずに tok/s を上げる手段
「帯域 ÷ モデルサイズ」が上限を決める、という大原則は変わりません。ただ、ハードを買い替えなくても実効の tok/s を引き上げる手はいくつかあります。整理しておきます。
- モデルサイズ(GB)を減らす:量子化で重みを軽くすれば、式の分母が小さくなり tok/s が上がります。どのフォーマットでどれだけ軽くなるかは「ローカルLLMの量子化フォーマットとは 2026年版」を参照
- 投機的デコードを使う:小さなドラフトモデルに数トークン先読みさせ、大モデルが一括検証する手法です。**出力は大モデル単体と完全に一致(ロスレス)**したまま、コード生成・構造化出力で1.5〜3倍速くなります。帯域もモデルサイズも変えずソフト側だけで効くのが特徴。詳しくは「投機的デコード(Speculative Decoding)とは 2026年版」で解説しています
逆に「GPUのTOPSや演算性能を上げる」のは decode の tok/s にはほぼ効きません。tok/s を上げたいなら、帯域を上げる(ハード)か、モデルを小さくする(量子化)か、先読みで確定を稼ぐ(投機的デコード)か。この3方向で考えるのが正解です。なお実際のGPU別 tok/s 実測は「Llama 3.3 70B GPU別トークン/秒 2026年版」に並べています。
入手先・関連商品
当サイトは Amazon.co.jp アソシエイト・プログラムに参加予定です。下記リンク経由で購入された場合、紹介料を受け取ることがあります。読者の負担は増えません。リンクは記事評価とは独立しており、編集判断には影響しません。
本文で帯域を比較したハードの参考リンクです。
- NVIDIA GeForce RTX 5090 を Amazon.co.jp で見る
- Mac Studio M4 Max を Amazon.co.jp で見る
- Beelink GTR9 Pro Ryzen AI MAX+ 395 を Amazon.co.jp で見る
あなたに合うPCを診断する
用途や予算をもう少し細かく入力すると、3つの候補構成を提案します。
→ 診断スタート