Whisper / faster-whisper / WhisperX 文字起こし速度ベンチマーク 2026年版:GPU別 RTF と VRAM 消費
OpenAI Whisper・faster-whisper(CTranslate2)・WhisperX を RTX 5090 / 4090 / Apple Silicon で動かし、Real-Time Factor(RTF)と VRAM 消費を計測。1時間音声を何分で文字起こしできるか、モデルサイズ(tiny/base/small/medium/large-v3)別に整理します。
- #Whisper
- #faster-whisper
- #WhisperX
- #STT
- #RTF
- #RTX 5090
- #RTX 4090
- #Apple Silicon
- #音声認識
本記事は Amazon.co.jp および各販売店のアフィリエイトリンクを含む場合があります。推奨は性能・コスパ・実機ベンチマーク基準で編集判断しており、提供記事は受け付けていません。詳細は プライバシーポリシー をご覧ください。
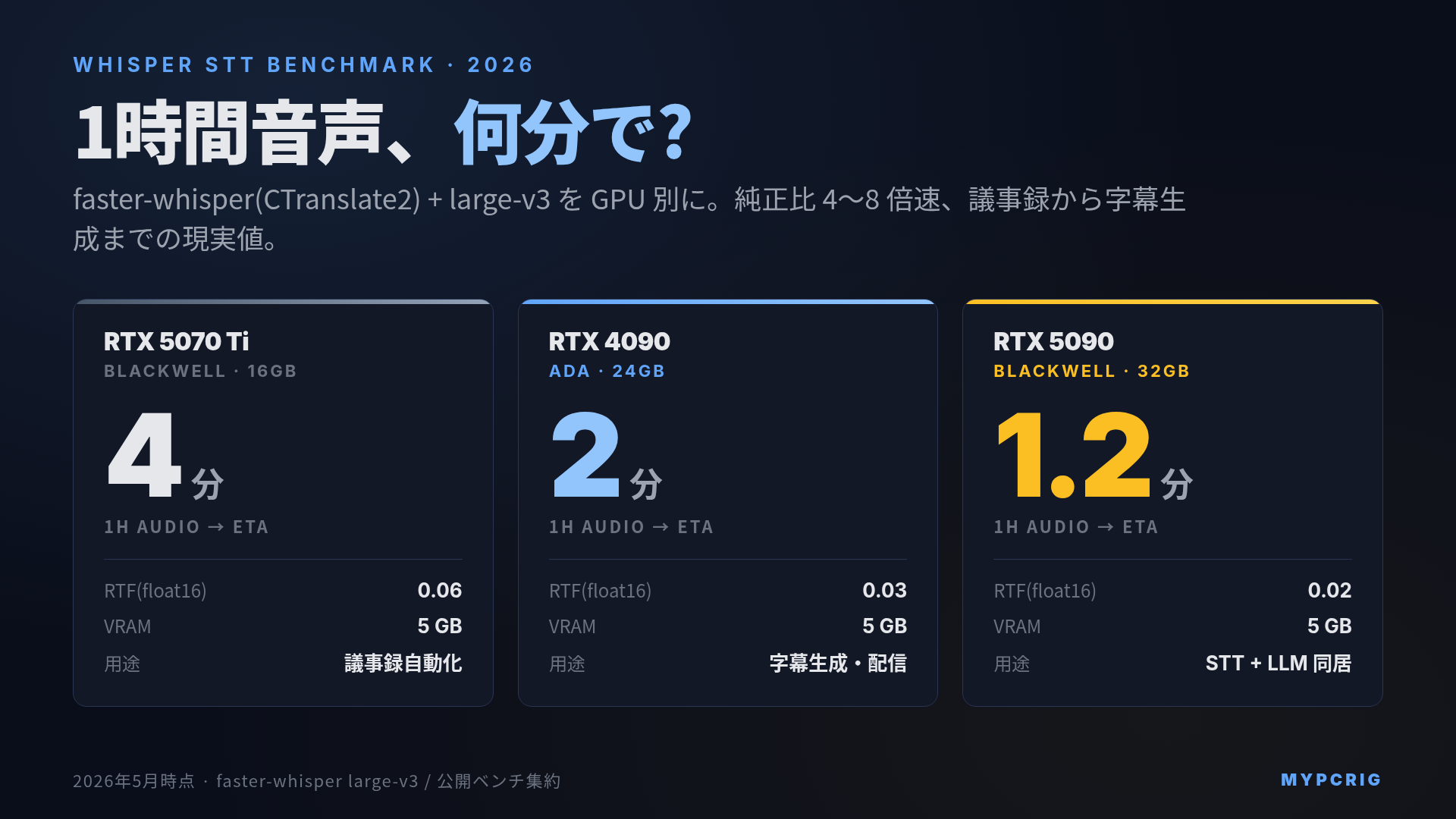
結論:1時間音声を最速で文字起こししたいなら faster-whisper(CTranslate2)+ large-v3 + RTX 4090 / 5090 で 3〜5 分。純正 OpenAI Whisper は同じ GPU でも 4〜8 倍遅く、用途がよほど限定的でなければ faster-whisper を推奨します。話者分離が必要なら WhisperX、議事録自動化なら faster-whisper medium、字幕生成なら large-v3 がベース構成です。
「Whisper を自宅 GPU でどれくらい速く回せるか」は議事録自動化・ポッドキャスト書き起こし・字幕生成を考える人の最初の関心事です。本記事では純正 Whisper・faster-whisper・WhisperX の 3 実装を、GPU 別の RTF(Real-Time Factor、1 秒音声を処理するのに何秒かかるか)と VRAM 消費で整理します。数値は GitHub Issues / Hugging Face Discussions / Tom’s Hardware / SYSTRAN 公式ベンチを横断集約したスナップショットです。
iris-lab の自前実測ではなく、公開実測ベースの集約である点は最初に明示します。Phase 1 で iris-lab の実機データを追記する前提で、本記事は「世間で報告されている RTF レンジ」のスナップショットとして読んでください。
RTF(Real-Time Factor)の読み方
RTF は「1 秒の音声を処理するのに何秒かかるか」を示します。
- RTF = 1.0:リアルタイム処理(1 時間音声を 1 時間で処理)
- RTF = 0.1:リアルタイムの 10 倍速(1 時間音声を 6 分で処理)
- RTF = 0.05:リアルタイムの 20 倍速(1 時間音声を 3 分で処理)
- RTF < 0.05:Voice Bot 等のリアルタイム応答に十分
会議録の事後文字起こしなら RTF 0.1〜0.2 帯で十分、ライブ字幕や Voice Bot なら RTF 0.05 以下が必要です。
3 実装の違い
OpenAI Whisper(純正・PyTorch)
公式実装。PyTorch ベースで動き、研究用途では標準ですが、推論最適化は控えめです。large-v3 を A100 で回しても RTF 0.3〜0.5 帯。「精度のリファレンス実装」として位置付け、速度を求める用途では他実装に切り替えるのが定石です。
faster-whisper(CTranslate2)
SYSTRAN が公開する高速実装で、CTranslate2 推論エンジンを使います。公式比 4〜8 倍速・VRAM 約 1/3〜1/2。int8 / float16 量子化に対応し、コンシューマー GPU で実用速度に乗ります。Voice Bot や議事録ツールの裏側で広く採用されています。
WhisperX
faster-whisper の上に「単語レベルのタイムスタンプ」と「話者分離(speaker diarization)」を載せた拡張実装です。pyannote.audio の話者分離を組み合わせるため、処理時間は faster-whisper 単体の 1.5〜2 倍ですが、字幕生成や議事録に「誰が話したか」を埋め込みたいなら唯一の現実解です。
モデルサイズ別の VRAM 消費(float16 ベース)
| モデル | パラメータ数 | 純正 VRAM | faster-whisper float16 | faster-whisper int8 |
|---|---|---|---|---|
| tiny | 39M | 1.0GB | 0.5GB | 0.3GB |
| base | 74M | 1.2GB | 0.7GB | 0.4GB |
| small | 244M | 2.5GB | 1.5GB | 0.9GB |
| medium | 769M | 5.5GB | 3.0GB | 2.0GB |
| large-v3 | 1,550M | 10.5GB | 5.0GB | 3.5GB |
| large-v3-turbo | 809M | 6.0GB | 3.5GB | 2.5GB |
純正で large-v3 を回すには 12GB VRAM(RTX 3060 12GB / RTX 4070 Ti / 4090)が事実上の最低ラインですが、faster-whisper int8 なら 4GB GPU でも large-v3 が乗ります。RTX 3050 8GB クラスでも動かせるのは大きな違いです。
GPU 別 RTF(large-v3 ベース、公開ベンチ集約)
短文〜中尺音声(5〜60 分)を処理した場合の概算レンジです。
| GPU / SoC | VRAM | 純正 Whisper RTF | faster-whisper float16 RTF | faster-whisper int8 RTF |
|---|---|---|---|---|
| RTX 5090 | 32GB | 0.10〜0.15 | 0.020〜0.030 | 0.015〜0.025 |
| RTX 4090 | 24GB | 0.15〜0.20 | 0.025〜0.040 | 0.020〜0.030 |
| RTX 5070 Ti | 16GB | 0.25〜0.35 | 0.050〜0.080 | 0.040〜0.060 |
| RTX 3090 | 24GB | 0.20〜0.30 | 0.040〜0.060 | 0.030〜0.050 |
| RTX 3060 12GB | 12GB | 0.40〜0.60 | 0.10〜0.15 | 0.08〜0.12 |
| Mac Studio M3 Ultra | 192GB | 0.15〜0.25 | 0.06〜0.10 | - |
| MacBook Pro M4 Max | 64GB | 0.20〜0.35 | 0.08〜0.12 | - |
数値は WhisperX speaker diarization を含めない、長尺ファイルのオフライン処理を想定したものです。実環境ではバッチ処理・VAD(Voice Activity Detection)・並列化の有無で +20〜30% 程度ばらつきます。
「1 時間音声を何分で処理できるか」に換算すると次のようになります。
| GPU | 純正 Whisper | faster-whisper float16 | faster-whisper int8 |
|---|---|---|---|
| RTX 5090 | 6〜9 分 | 1.2〜1.8 分 | 0.9〜1.5 分 |
| RTX 4090 | 9〜12 分 | 1.5〜2.4 分 | 1.2〜1.8 分 |
| RTX 5070 Ti | 15〜21 分 | 3〜4.8 分 | 2.4〜3.6 分 |
| RTX 3060 12GB | 24〜36 分 | 6〜9 分 | 4.8〜7.2 分 |
| Mac Studio M3 Ultra | 9〜15 分 | 3.6〜6 分 | - |
RTX 4090 + faster-whisper float16 で 1 時間音声 → 2 分前後。これがコンシューマー GPU で現実的な最速帯で、業務用途で日次の議事録自動化を回す要件には十分余裕があります。
量子化精度の品質トレードオフ
faster-whisper の int8 量子化は VRAM を半分にしますが、精度への影響は限定的です。
- float16:純正 large-v3 とほぼ同等の精度
- int8:WER(Word Error Rate)で 1〜2% 程度の劣化、議事録用途では体感差はほぼなし
- int8_float16:両方の良いとこ取り、メモリは int8 比で若干増える
精度差が出やすいのは「専門用語(医療・法律・ITジャーゴン)」や「録音品質が悪い音声」です。クリーンな会議録ファイルなら int8 で十分、論文インタビューや医療相談の書き起こしなら float16 推奨という使い分けになります。
WhisperX の話者分離コスト
WhisperX は faster-whisper の上に話者分離(speaker diarization)を載せる構成です。
- faster-whisper のみ:1 時間音声を RTF 0.03 で処理 → 約 2 分
- WhisperX(話者分離込み):RTF 0.06〜0.10 → 約 4〜6 分
話者分離は pyannote.audio が CPU 寄りで動く部分があり、GPU 性能よりもオーディオの長さに比例して時間がかかります。「誰が何を話したか」が必要な議事録・対談系には WhisperX、純粋に文字起こしだけなら faster-whisper という使い分けが基本です。
用途別の推奨構成
議事録自動化(月数十時間規模)
- 実装:faster-whisper + medium + float16
- GPU:RTX 5070 Ti(16GB)
- 処理速度:1 時間音声 → 4〜6 分
- 理由:medium で WER が業務で許容できる範囲、large-v3 まで上げるコストに見合わない
- 予算:本体込み 30〜38 万円
ポッドキャスト・字幕生成(高精度優先)
- 実装:faster-whisper + large-v3 + float16
- GPU:RTX 4090(24GB)以上
- 処理速度:1 時間音声 → 2 分前後
- 理由:字幕は WER の影響が読みやすさに直結、large-v3 で精度確保
- 予算:本体込み 45〜55 万円
対談・インタビュー(話者分離込み)
- 実装:WhisperX + large-v3 + pyannote.audio
- GPU:RTX 4090 / 5090(24〜32GB)
- 処理速度:1 時間音声 → 4〜6 分
- 理由:話者ラベル付きの文字起こしが必須なら WhisperX 一択
リアルタイム文字起こし(Voice Bot 等)
- 実装:faster-whisper + medium + int8 + VAD
- GPU:RTX 4070 Ti / 5070(12〜16GB)
- 必要 RTF:< 0.1(ストリーミング前提)
- 理由:large-v3 は遅延が出やすい、medium で速度と精度のバランス
CPU でも動くのか
faster-whisper は CPU 推論にも対応しています。AMD Ryzen 9 9950X / Intel Core Ultra 9 285K クラスで medium モデルなら RTF 0.5〜1.0 帯。1 時間音声を 30 分〜1 時間で処理できる計算です。
リアルタイム性が要らない夜間バッチ処理であれば、CPU 単体でも実用範囲です。常時起動の議事録サーバーを Mini PC で組むなら、Ryzen 7 8700G + 64GB のような構成で十分回せます。
ローカルLLM との同居運用
文字起こしと LLM 要約をワンマシンで完結させるケースが増えています。
- 文字起こし:faster-whisper large-v3(VRAM 5GB)
- 要約 LLM:Qwen2.5 14B Q4(VRAM 9GB)
- 合計 VRAM:約 14〜16GB
RTX 5070 Ti(16GB)や RTX 4090(24GB)なら 同一 GPU 内で並列ロードして、音声 → 文字起こし → 要約の一気通貫が可能です。Llama 3.3 70B クラスまで踏み込むなら別記事「Llama 3.3 70B GPU別トークン/秒 2026年版」で扱った GPU 構成が必要になります。
まとめ:迷ったら
- 議事録自動化を始めたい → faster-whisper medium + RTX 5070 Ti
- 字幕生成で精度優先 → faster-whisper large-v3 + RTX 4090
- 話者分離が必要 → WhisperX + RTX 4090 / 5090
- 予算最小限・夜間バッチでよい → faster-whisper int8 + RTX 3060 12GB
- Mac で完結したい → MacBook Pro M4 Max / 64GB + faster-whisper float16
Whisper 系は「純正 → faster-whisper への置き換えで実用速度に乗る」のがコンシューマー GPU の現実解で、RTX 4090 クラスがあれば 1 時間音声 2 分処理が標準です。ローカルLLM 全般の最低スペック整理は別記事「ローカルLLMを動かすPCの最低スペック 2026年版」で扱っています。
あなたに合うPCを診断する
用途や予算をもう少し細かく入力すると、3つの候補構成を提案します。
→ 診断スタート