Apple M5 / M5 Pro / M5 Max ローカルLLM 実測ベンチマーク 2026年版:tok/sec とメモリ帯域でM4世代からどれだけ伸びたか
Apple M5世代でローカルLLMはどこまで速くなったか。M5 / M5 Pro / M5 Max を対象に、Llama 3 8B・70B や Qwen3.5 MoE をMLXで動かしたtok/secと、614GB/s(M5 Max)/307GB/s(M5 Pro)というメモリ帯域差が推論速度に与える影響を整理し、M4世代から買い替える価値があるかを判断します。
- #Apple M5
- #M5 Max
- #M5 Pro
- #ローカルLLM
- #MLX
- #メモリ帯域
- #tok/sec
- #ベンチマーク
本記事は Amazon.co.jp および各販売店のアフィリエイトリンクを含む場合があります。推奨は性能・コスパ・実機ベンチマーク基準で編集判断しており、提供記事は受け付けていません。詳細は プライバシーポリシー をご覧ください。
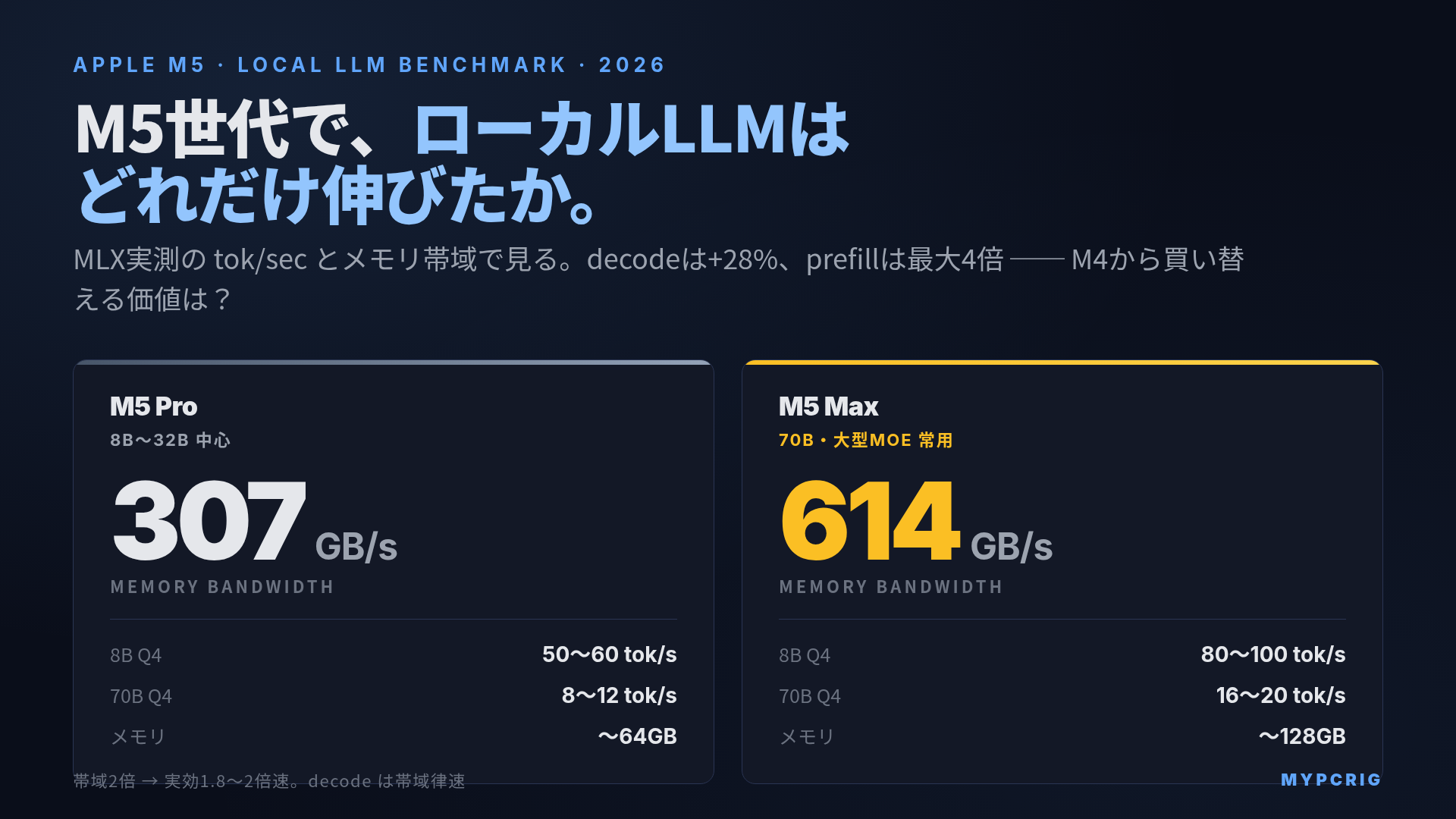
結論:8B〜14B中心ならM5 Pro、70B以上・大型MoEを常用するならM5 Max(または上位のMac Studio Ultra系)です。M5 Max は M4 Max比でトークン生成が約+28%、プロンプト処理(prefill)は最大4倍に伸びました。ただし帯域増は約12.5%(546→614GB/s)に過ぎず、伸びの大半は各GPUコアに新搭載された Neural Accelerator 由来です。M4世代からの買い替えは「8B〜14Bを対話で使うだけなら不要寄り、70B以上・長文prefillを多用するなら価値大」が現実的な線引きです。
Apple M5世代が登場し、ローカルLLM界隈で「結局どれだけ速くなったのか」が話題になっています。数字は派手に見えても、メモリ帯域の伸びは控えめ。一方でprefillは大きく改善した、という少しややこしい世代です。
私はこの記事で、M5 / M5 Pro / M5 Max を対象に、MLXで動かしたトークン生成速度(tok/sec)とメモリ帯域の関係を整理します。数値はコミュニティのMLXベンチと公開レビューを出典付きで集約し、レンジで提示します(断定しすぎません)。実機での再現計測は入手次第このページに追記します。
まず帯域とアーキの前提を揃える
| 項目 | M5 Pro | M5 Max |
|---|---|---|
| メモリ帯域 | 約307 GB/s | 約614 GB/s |
| 最大メモリ | 〜64GB | 〜128GB |
| GPUコア | Neural Accelerator 内蔵 | Neural Accelerator 内蔵 |
| 帯域比(M5 Pro基準) | 1.0x | 約2.0x |
| 対M4 Max帯域 | ─ | +約12.5%(546→614GB/s) |
M5世代の最大の変更点は、各GPUコアに Neural Accelerator が内蔵されたことです。従来は固定サイズの Neural Engine がAI処理を担っていましたが、M5ではGPUコア側に演算器が分散し、特にprefill(プロンプト処理)が大きく速くなりました。
ここで重要なのは、トークン生成(decode)は依然メモリ帯域律速である点です。1トークン生成するたびにモデル全重みをメモリから読むため、帯域が天井になります。この仕組みは「メモリ帯域幅(GB/s)がローカルLLMの tok/sec を決める仕組み 2026年版」で詳しく解説しています。帯域増が+12.5%なのに生成が+28%伸びた理由も、Neural Accelerator による効率改善が帯域以外の部分を底上げしたからです。
トークン生成(decode)の実測レンジ
MLX・Q4基準でのトークン生成速度の目安です。コミュニティ実測のレンジで示します。
| モデル | M5 Pro(307GB/s) | M5 Max(614GB/s) |
|---|---|---|
| Llama 3 8B Q4 | 約50〜60 tok/s | 約80〜100 tok/s |
| Qwen3.5 30B-A3B MoE Q4 | 約30〜40 tok/s | 約55〜60 tok/s |
| Llama 3 70B Q4 | 約8〜12 tok/s | 約16〜20 tok/s |
参考までに、ある実測ではM5 Maxの Llama 3 8B Q4 が約82 tok/s、Qwen 3.5 30B-A3B Q4 が約58 tok/s、Llama 3 70B Q4 が約18 tok/s と報告されています。M5 Pro はおおむねその5〜6割の速度帯です。
ここで効いているのが帯域差です。M5 Max(614)vs M5 Pro(307)≒ 帯域2倍で、生成速度も実効で約1.8〜2倍に開きます。帯域律速の理論どおりの挙動です。「8Bを軽く使うだけならM5 Proでも十分速い、70Bを実用速度で回したいならM5 Max」という線引きが、この表から読み取れます。
M4世代からの伸び:+28%の中身
最大の関心事「M4から何が変わったか」を整理します。
| 指標 | M4 Max → M5 Max |
|---|---|
| トークン生成(8B Q4) | 約64 → 約82 tok/s(約+28%) |
| メモリ帯域 | 546 → 614 GB/s(+約12.5%) |
| プロンプト処理(prefill) | 最大約4倍 |
生成速度の+28%は、帯域増(+12.5%)だけでは説明できません。差分は Neural Accelerator によるGPUコアの演算効率改善が埋めています。そして見逃せないのがprefillの最大4倍。長いコンテキスト(リポジトリ投入・RAG・長文要約)を扱う用途では、生成速度より「最初のトークンが出るまで」の体感がこちらで決まります。prefillが用途を左右する理由は「ローカルLLM プロンプト処理(prefill)速度 GPU別ベンチマーク 2026年版」で掘り下げています。
つまりM5世代は「対話でtok/secを少し稼ぐ世代」というより、「長文・エージェント用途のprefillが本命の世代」と捉えるのが正確です。
容量別に動かせるモデル規模
| メモリ容量 | 現実的に快適なモデル |
|---|---|
| 24GB(M5 Pro) | 8B〜14B Q4、軽い30B MoE |
| 48GB(M5 Pro / Max) | 〜32B Q4、30B級MoE、70B Q4はギリギリ |
| 128GB(M5 Max) | 70B Q4 余裕、120B級MoE、長コンテキスト常用 |
70B以上を快適に回す・長いコンテキストを常用するなら、128GBを積める M5 Max が安心です。M5 Pro(最大64GB)は8B〜32B級が主戦場になります。
買い替え・選び方の結論
| あなたの状況 | おすすめ |
|---|---|
| 8B〜14Bを対話で使う中心 | M5 Pro(コスパ良好) |
| 70B以上・大型MoEを常用 | M5 Max(128GB) |
| 長文・RAG・エージェントでprefill重視 | M5世代(特にM5 Max)に更新する価値大 |
| M4で8B〜14Bに満足している | 買い替えの必然性は薄め |
| 300GB超の超巨大モデルを載せたい | M5ではなく Mac Studio M3 Ultra(512GB)系 |
私の総括はこうです。M5は「decodeを少し速く、prefillを大きく速く」した世代。 8B〜14Bを対話で使うだけのM4ユーザーなら、+28%のために買い替える必然性は薄い。逆に70B以上を常用する、あるいは長文コンテキストのprefillの遅さに不満があるなら、M5 Maxへの更新価値ははっきり大きい。動かすモデルの規模と、decode/prefillのどちらが効く用途かで決めてください。
同じMac内での世代・グレード比較は「Mac Studio M4 Max vs M3 Ultra ローカルLLM ベンチマーク 2026年版」と「MacBook Pro M5 Max vs Mac Studio M4 Max / M3 Ultra 2026年版」で詳しく扱っています。
入手先・関連商品
当サイトは Amazon.co.jp アソシエイト・プログラムに参加予定です。下記リンク経由で購入された場合、紹介料を受け取ることがあります。読者の負担は増えません。リンクは記事評価とは独立しており、編集判断には影響しません。
M5 Pro / M5 Max 搭載機
- MacBook Pro M5 Pro を Amazon.co.jp で見る
- MacBook Pro M5 Max を Amazon.co.jp で見る
- Mac Studio M5 Max を Amazon.co.jp で見る
あなたに合うPCを診断する
用途や予算をもう少し細かく入力すると、3つの候補構成を提案します。
→ 診断スタート